
 Publicado por el Dr Rafael Ramírez del departamento de otorrino de la clinica fivasa.
Publicado por el Dr Rafael Ramírez del departamento de otorrino de la clinica fivasa.
Los pacientes que requieren una prótesis auditiva no siempre pueden
llevarla, ya que, en ocasiones se producen problemas en su conducto
auditivo que les impiden disfrutar de una audición cómoda. Infecciones
de repetición, tapones de cerumen, o simplemente un conducto con una
anatomía alterada, hacen que el uso de un audífono convencional sea
muy complicado.
En otras ocasiones el paciente tiene un trabajo o unas aficiones que
le es difícil desempeñar con una prótesis convencional, como por
ejemplo personas que trabajan en ambientes húmedos o incluso bajo del
agua, teniendo que prescindir de estas prótesis. Por eso mismo
queremos que conozcan una alternativa que puede servir para estos
casos: el implante Carina®, representa la alternativa a los sistemas
auditivos convencionales, aportando la ultima tecnología para mejorar
su calidad de vida auditiva.
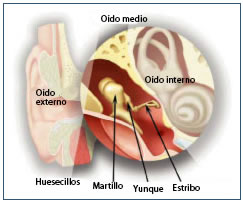
Se trata de un dispositivo totalmente implantable, mediante cirugía,
que se coloca detrás de la oreja, debajo de la piel, quedando
totalmente invisible. Este sistema auditivo capta el sonido a través
de un micrófono situado también debajo de la piel y lo envía a un
transductor que lo conduce directamente a los huesecillos del oído
medio. Se trata de un audífono con una calidad del sonido muy natural,
ya que no es necesario que el oído esté tapado por un molde,
solventándose las molestias del efecto oclusión
El dispositivo se a través de un control remoto, pudiéndose regular
tanto la puesta en marcha como el control del volumen
No todo el mundo puede utilizar este dispositivo, ya que , como
cualquier otra prótesis, tiene unos límites de efectividad, siendo una
prótesis ideal para pérdidas auditivas moderadas a severas. Tampoco es
recomendable utilizar el sistema Carina® como primera prótesis
auditiva, no siendo aconsejable su implantación en paciente que nunca
hayan utilizado una prótesis convencional. Lo primero sería valorar si
usted cumple los criterios audiologicos que le permitirían
beneficiarse del implante, para ello, tendríamos que realizar unas
pruebas audiológicas: audiometría tonal liminar y una prueba de
discriminación verbal con y sin prótesis auditiva que nos permitirían
valorar la ganancia que podría obtener con el Carina®.
La clínica Fivasa es un centro donde usted puede conocer mejor este
sistema y nuestros especialistas pueden realizar el implante del
llevarla, ya que, en ocasiones se producen problemas en su conducto
auditivo que les impiden disfrutar de una audición cómoda. Infecciones
de repetición, tapones de cerumen, o simplemente un conducto con una
anatomía alterada, hacen que el uso de un audífono convencional sea
muy complicado.
En otras ocasiones el paciente tiene un trabajo o unas aficiones que
le es difícil desempeñar con una prótesis convencional, como por
ejemplo personas que trabajan en ambientes húmedos o incluso bajo del
agua, teniendo que prescindir de estas prótesis. Por eso mismo
queremos que conozcan una alternativa que puede servir para estos
casos: el implante Carina®, representa la alternativa a los sistemas
auditivos convencionales, aportando la ultima tecnología para mejorar
su calidad de vida auditiva.
Se trata de un dispositivo totalmente implantable, mediante cirugía,
que se coloca detrás de la oreja, debajo de la piel, quedando
totalmente invisible. Este sistema auditivo capta el sonido a través
de un micrófono situado también debajo de la piel y lo envía a un
transductor que lo conduce directamente a los huesecillos del oído
medio. Se trata de un audífono con una calidad del sonido muy natural,
ya que no es necesario que el oído esté tapado por un molde,
solventándose las molestias del efecto oclusión
El dispositivo se a través de un control remoto, pudiéndose regular
tanto la puesta en marcha como el control del volumen
No todo el mundo puede utilizar este dispositivo, ya que , como
cualquier otra prótesis, tiene unos límites de efectividad, siendo una
prótesis ideal para pérdidas auditivas moderadas a severas. Tampoco es
recomendable utilizar el sistema Carina® como primera prótesis
auditiva, no siendo aconsejable su implantación en paciente que nunca
hayan utilizado una prótesis convencional. Lo primero sería valorar si
usted cumple los criterios audiologicos que le permitirían
beneficiarse del implante, para ello, tendríamos que realizar unas
pruebas audiológicas: audiometría tonal liminar y una prueba de
discriminación verbal con y sin prótesis auditiva que nos permitirían
valorar la ganancia que podría obtener con el Carina®.
La clínica Fivasa es un centro donde usted puede conocer mejor este
dispositivo Carina®






{kind=link}